南湖新闻网讯(通讯员 王烁)近日,明星换脸av 罗俊副教授课题组的研究成果“OntoAug: Rethinking Generative Data Augmentation via Ontology Guidance”被国际计算机视觉会议 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR 2026)录用。
当人工智能的发展不断逼近人类认知边界,我们是否可以从“人如何理解世界”这一根本问题中寻找启发?研究团队认为,人类进行类别识别时,往往抓住事物的“本质属性”,同时容忍环境与背景的变化——正所谓“万变不离其宗”。正是这种“主体稳定、环境可变”的认知机制,为生成式数据增强提供了新的思想来源。
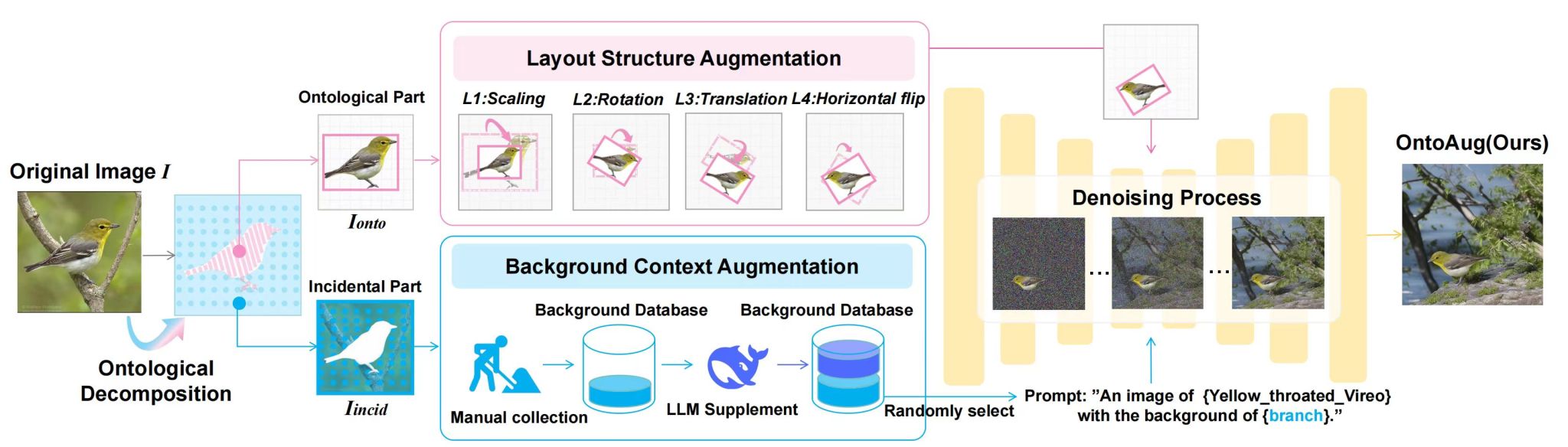
当前生成式数据增强方法虽能提升样本多样性,但普遍将图像视为不可分割的整体,忽视前景主体与背景环境在语义层级上的差异,容易造成主体语义漂移或场景不协调等问题。围绕这一关键挑战,团队提出了一种基于“本体—环境”区分思想的生成式数据增强新框架——OntoAug。
OntoAug首次从本体论视角出发,将图像显式划分为“本体部分”(前景主体)与“偶然部分”(背景环境),构建了面向主体语义保护的增强范式。方法通过前景掩码约束与结构化布局控制,引导扩散模型在保持主体核心语义稳定的前提下生成多样化背景,从而实现“稳定主体、多样背景、整体协调”的协同优化。

在技术实现上,OntoAug对前景区域进行结构层级的布局增强,仅允许在空间位置与构图层面进行合理变换,避免改变类别本质属性;同时构建多源背景语义库,引入大语言模型辅助扩展背景语义空间,显著提升场景组合的丰富性与自然度。最终,通过扩散模型实现前景与背景的统一生成,确保图像整体语义连贯。
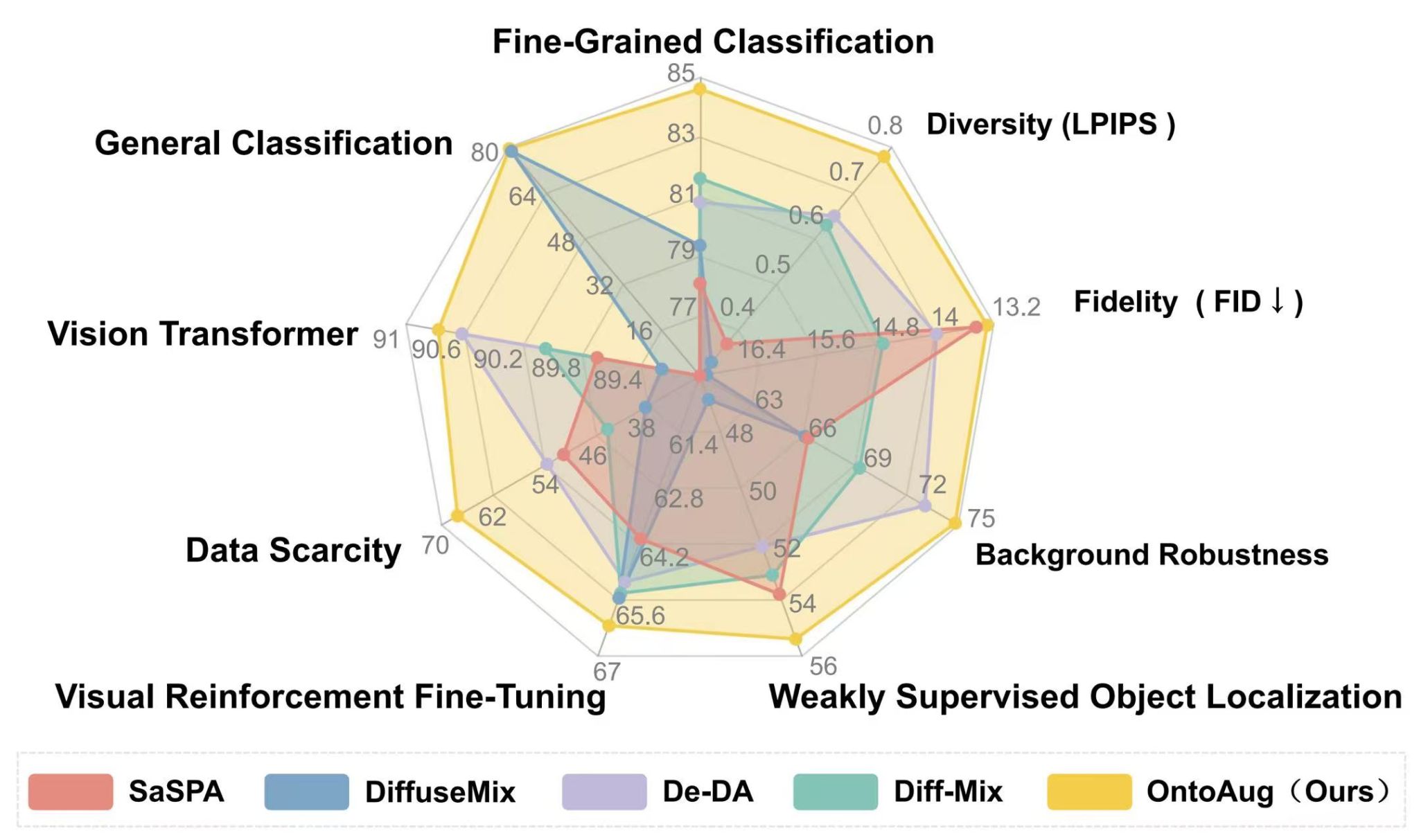
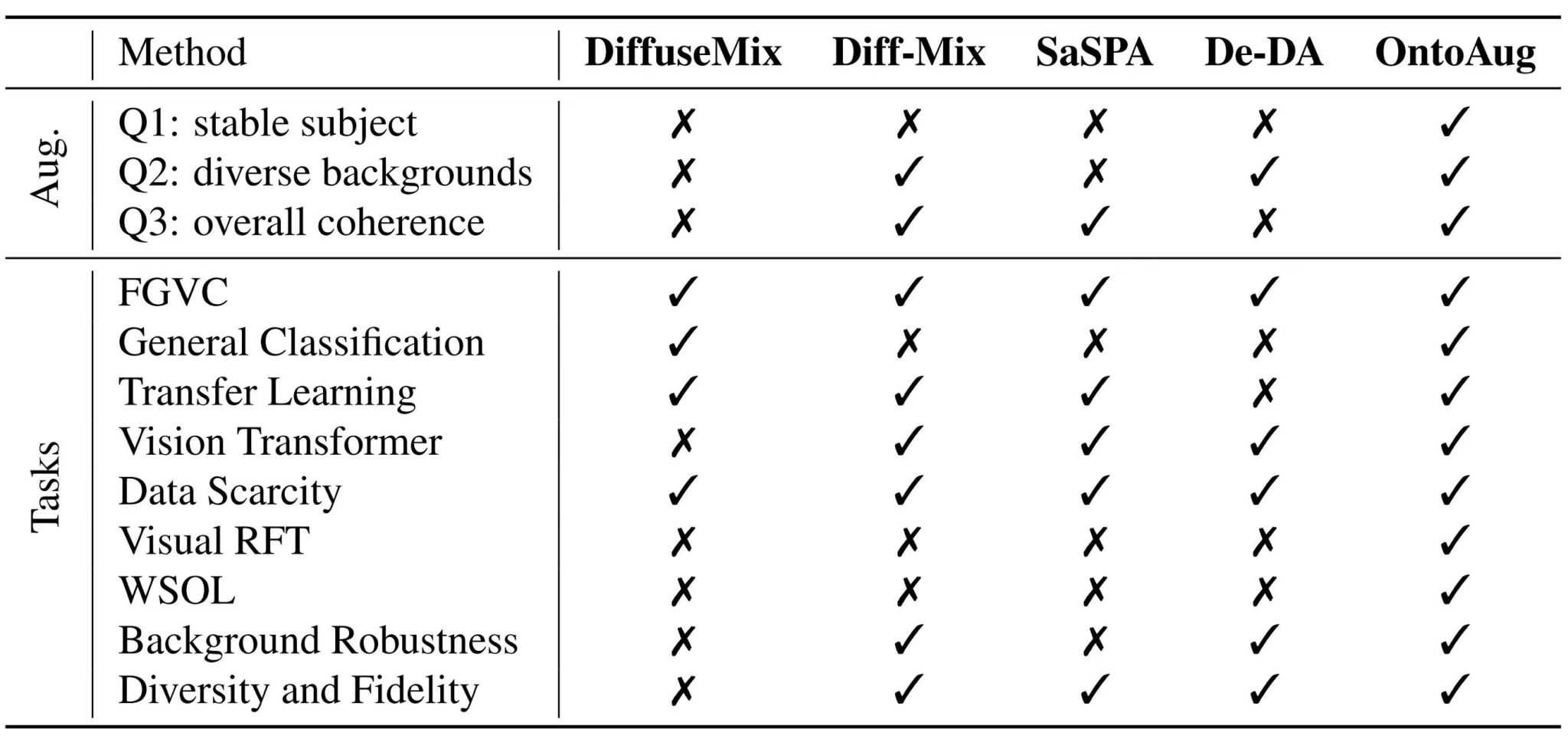
大量实验结果表明,OntoAug在图像分类、小样本学习、弱监督目标定位以及多模态大模型推理等多项任务上均取得显著性能提升。在语义一致性与样本多样性之间实现更优平衡的同时,还能在数据受限场景下有效提升模型泛化能力,展现出良好的理论价值与应用潜力。
论文第一作者为明星换脸av 研究生王烁,罗俊副教授为论文通讯作者。CVPR是由IEEE与Computer Vision Foundation联合主办的计算机视觉领域国际顶级会议,是中国计算机学会(CCF)推荐的A类会议,在全球人工智能学术界具有重要影响力。
摘要:Generative data augmentation techniques open new avenues for improving image recognition models. The core of image recognition lies in accurately capturing the ontological features of the subject. However, existing methods often treat the image as a whole during augmentation, ignoring the uneven semantic distribution between foreground and background. This can lead to semantic shifts in generated samples, weakening the model’s ability to represent the subject’s ontology. In human perception, category recognition typically relies on the stable essence of the subject while tolerating variations in background and environment. Inspired by this human perceptual mechanism of “stable subjects, diverse backgrounds, and overall coherence,” we propose OntoAug, a data augmentation framework based on the distinction between ontology and environment that redefines the boundary of ontology-oriented enhancement. OntoAug explicitly separates the foreground subject and background context, guiding diffusion models through structured layout control to generate samples with consistent subjects and diverse backgrounds. Experiments show that OntoAug significantly improves performance in image classification, few-shot learning, weakly supervised object localization (WSOL), and large vision-language model (LVLM) reasoning, demonstrating its advantages in semantic fidelity and sample diversity. It offers a new direction for building visual systems more aligned with human perception.
审核:罗俊