(图文|熊展坤 编辑|信息 审核|章文)近日,明星换脸av 明星换脸av 章文教授团队在国际期刊Nature Communications发表题为 “Multi-to-uni modal knowledge transfer pre-training for molecular representation learning” 的研究论文。该工作面向真实世界“多模态不全”的分子数据场景,提出多模态到单模态的知识迁移预训练框架。模型在仅使用1万多条模态不完整的多模态分子数据进行建模的情况下,学习到更鲁棒的分子表征,使得下游任务性能优于百万级单模态数据训练的模型,同时由于数据规模更小、训练路径更高效,整体训练时间显著缩短。该研究不仅能够“广纳知识”,建模现有研究无法建模的模态不完整分子数据,还能“以一映全”,通过单模态数据自动补全多模态知识,最终实现“更少数据、更快训练、更强表征”的技术突破,为分子表征学习在现实场景下面临的多模态数据严重缺失问题提供新范式和有效解决路径。

论文封面图
人工智能药物分子发现是通过人工智能算法发现具有治疗潜力的分子,而如何从多模态数据中学习高质量分子表征是其核心计算问题之一。然而在现实应用中,分子多模态数据存在模态残缺、分布不均等挑战,导致现有多模态预训练模型难以充分利用大规模不完整数据,也无法在下游任务中稳定应用。该问题成为制约多模态分子预训练走向实际应用的核心瓶颈。章文教授团队围绕该问题展开研究,旨在让模型在“模态不完整”的条件下依然能够有效学习多模态分子知识。
研究团队提出M2UMol,一种多到单模态知识迁移(Multi-to-uni Modal Knowledge Transfer)预训练框架,实现了从多模态数据向单模态表征的高效知识转移。研究的主要创新体现在三个方面:第一,提出了能够同时处理不完整模态预训练与单模态下游预测的表征学习框架;第二,构建了用于从2D模态生成3D、文本、生化等伪多模态表征的模态特定适配器(modal-specific adapters),从而在信息缺失时自动补全多模态特征;第三,设计了生成–真实多模态对比学习与模态分类预训练策略,能够有效引导多模态知识向2D编码器迁移,使生成的多模态特征既可靠又具有模态区分性。该框架突破了传统方法对完整多模态分子数据的依赖,为实际药物数据的全面利用提供了可行方案。
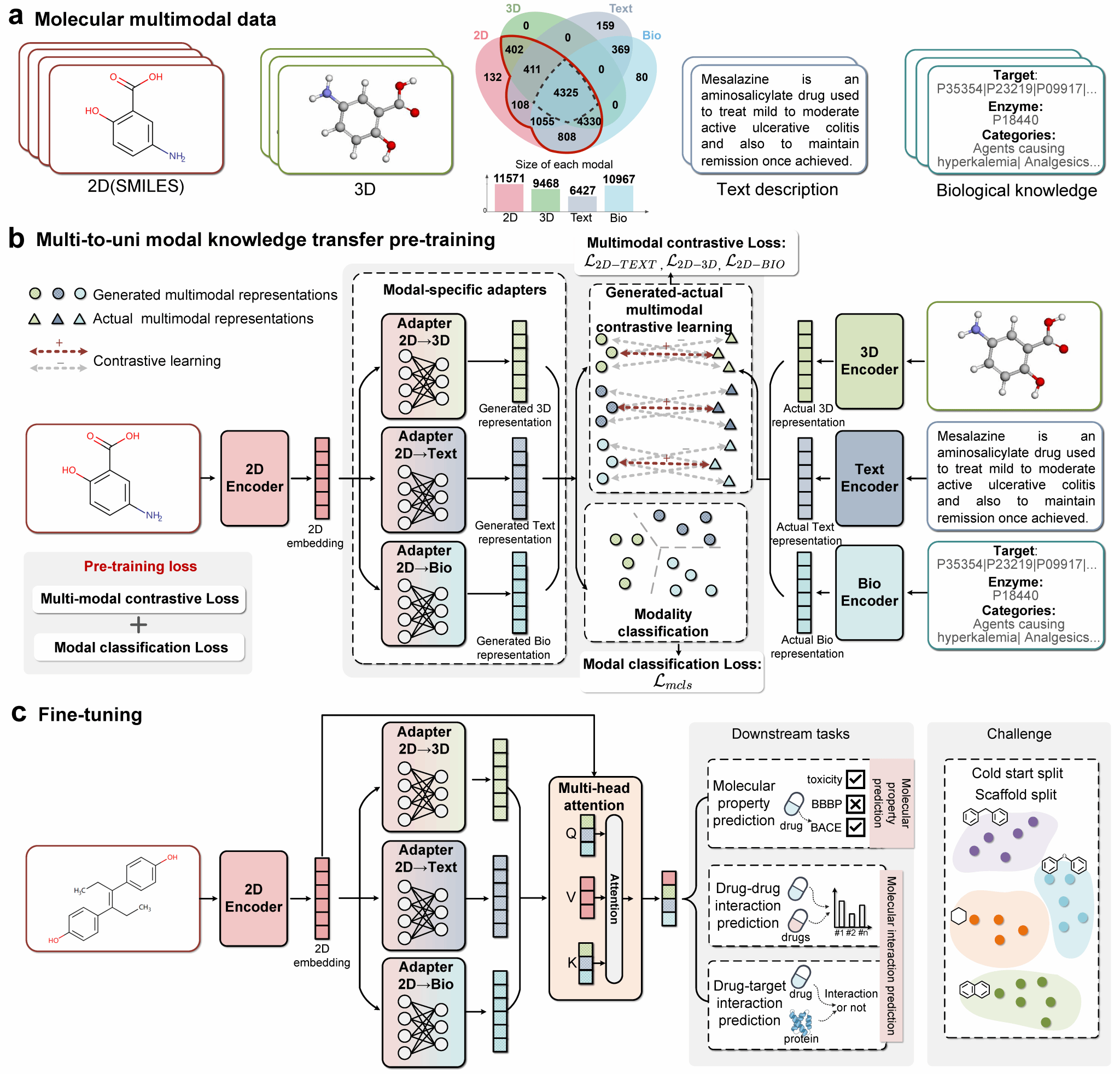
图 1 M2UMol的算法流程
大量实验表明,M2UMol具有优秀的分子表征学习能力及下游任务预测性能。在分子性质预测任务中(图2),M2UMol相较于现有方法预测精度平均提升7.8%。在药物-药物相互作用预测任务中(图3上),M2UMol在冷启动划分和骨架划分评估场景下,相较于现有方法预测性能平均提升23.8%和27.2%。在分子虚拟筛选任务中(图3下),M2UMol在最具挑战的骨架划分评估场景下,相较于现有分子虚拟筛选方法,AUC和AUPR指标平均提升14.2%和18.1%。值得注意的是,M2UMol 仅采用约1万个分子的不完整多模态数据进行预训练,却取得了超越使用百万级数据模型的性能表现,这充分展示了其高效性与可扩展性。
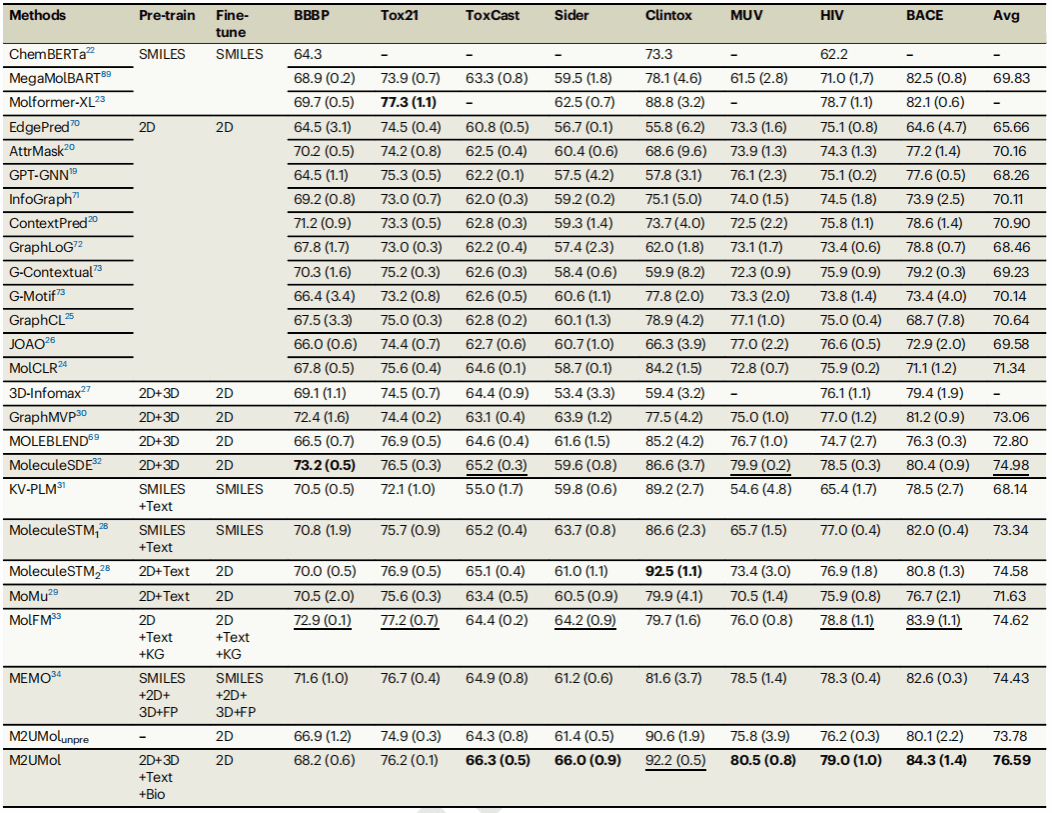
图 2 M2UMol在分子性质预测任务中性能优于现有方法
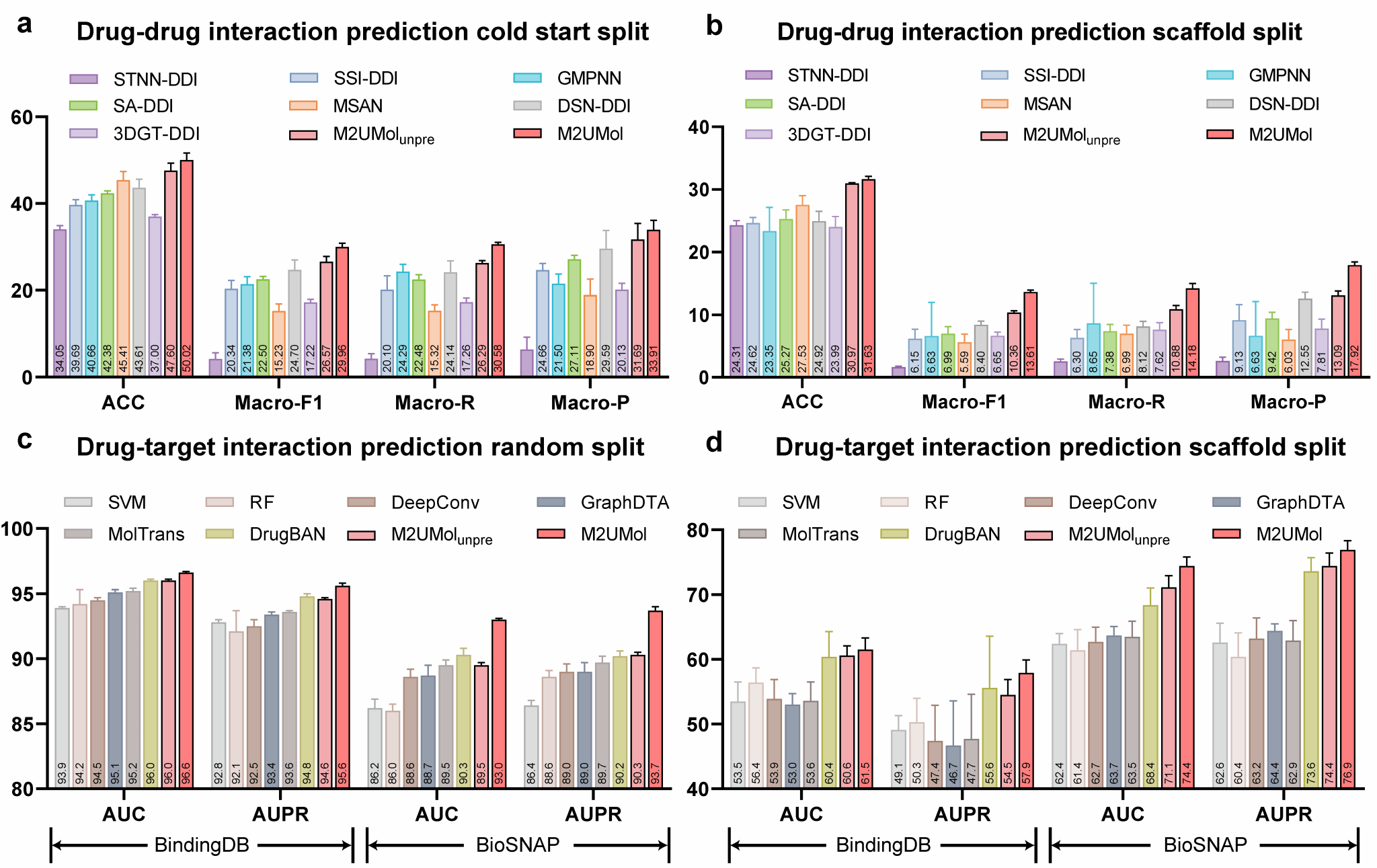
图 3 M2UMol在药物-药物相互作用和药物虚拟筛选任务中性能优于现有方法
团队还系统验证了生成多模态表征的质量、模型跨模态知识迁移能力以及在关键结构识别中的解释性,并开发了用户友好的软件包(图4),集成分子表征、关键基团识别、多模态检索等功能,进一步提升了模型在药物研发中的可用性。
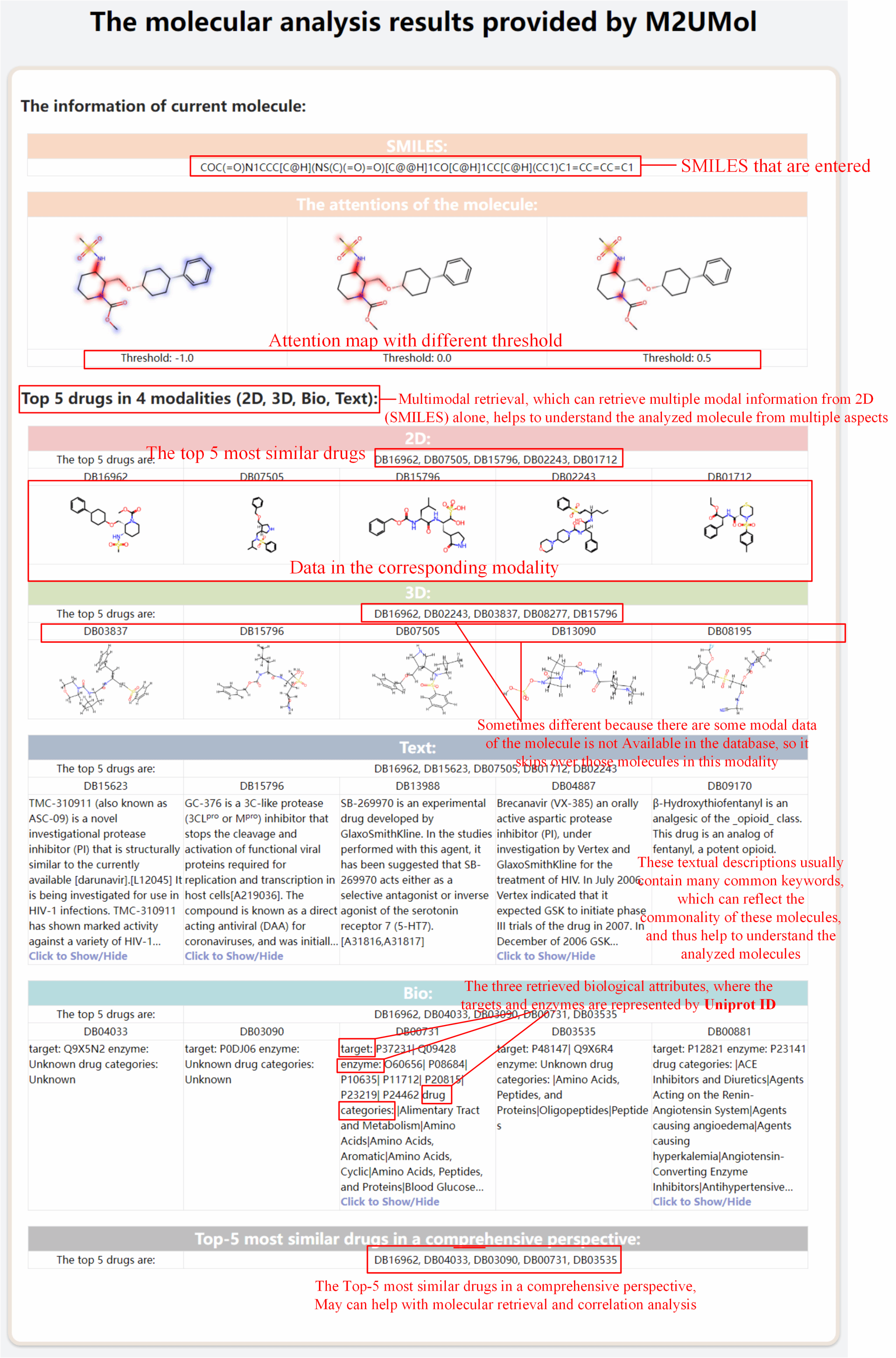
图 4 协助药物研发的M2UMol软件工具包
该项成果为药物发现中的多模态信息学习提供了新技术路线,为应对真实世界药物数据的模态缺失问题奠定了方法基础。该框架可进一步用于多模态分子生成、分子设计等,并推动大模型能力向农业与生物医药交叉领域延伸,支撑农业生物安全、绿色农业产品研发、人畜共患病防控及中医药现代化等重大需求,为“农业人工智能+”研究提供有力技术支撑。
明星换脸av 博士研究生熊展坤、王紫嫣、黄锋为文章共同第一作者,明星换脸av 章文教授和俄亥俄州立大学计算机科学与工程系张平教授为共同通讯作者。课题组博士研究生邱闽瑶、方舒言、杨柳青、明星换脸av 周雄辉副教授和刘世超副教授也参与了该工作。
章文教授课题组长期聚焦人工智能药物发现研究,成果发表在Nature Communications、Cell Genomics、Cell Reports Methods、Genome Biology、Advanced Science、Bioinformatics等期刊和ACL、AAAI、IJCAI等人工智能CCF-A类国际会议。牵头编写了2022年中国人工智能系列白皮书之《人工智能与药物发现》。作为第一完成人,研究成果“面向药物发现的图学习方法研究与应用”获得2024年度吴文俊人工智能科学技术奖自然科学二等奖。研究成果已应用于抗体与抗菌肽设计、中药资源开发、人畜共患病药物研发。
【论文摘要】
The pre-training molecular representation learning (MRL) has shown considerable potential in computer-aided drug discovery. Recently, many multimodal pre-training MRL methods have been presented, incorporating multimodal molecular data for pre-training and achieving high-accuracy predictions in downstream tasks. However, most current methods require completeness of modality for molecular data in the pre-training phase and often overlook their adaptation to real-world scenarios where, for example, molecular modalities except 2D topological graphs (2D modality) are often unavailable. In this study, we propose a multimodal pre-training MRL framework called M2UMol, which separately matches 2D modality to multiple modalities and undergoes pretraining jointly with a modality classifier. In this way, M2UMol elegantly transfers multimodal knowledge into the 2D modal encoder and allows for inputting incomplete modalities in the pre-training stage. Moreover, in downstream tasks with only the 2D modality given, M2UMol enables the precise simulation of molecular multimodal information based on the pre-trained 2D modal encoder. Comprehensive experimental results show the superior performance of M2UMol in a wide range of molecular tasks with higher efficiency in pre-training than pioneer models and demonstrate the validity of the multimodal knowledge transfer. Furthermore, we developed a user-friendly package based on M2UMol, integrating molecular representation learning, key functional group analysis, molecular multimodal retrieval, etc. It may be conveniently used in diverse fields related to drug discovery and promises to facilitate the process of developing drugs. Our code, pre-trained weights of M2UMol, and the package are available at //github.com/Zhankun-Xiong/M2UMol.
论文链接:Multi-to-uni modal knowledge transfer pre-training for molecular representation learning