(图文|郑彦松 编辑|辛西 审核|何新卫)近日,明星换脸av 何新卫老师课题组的研究成果“DINO Eats CLIP: Adapting Beyond Knowns for Open-set 3D Object Retrieval”被国际计算机视觉会议 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR 2026)录用。
人工智能时代浪潮奔涌,各类大模型竞相涌现。其中,视觉基础模型在开放集三维物体检索领域展现出巨大潜力。然而,现有方法(如微调CLIP编码器构建三维表征)仍面临挑战:尽管能构建语义对齐的特征空间,却存在细粒度信息丢失的问题,且容易过度拟合已知类别的视角共性,导致对未知类别的泛化能力不足。
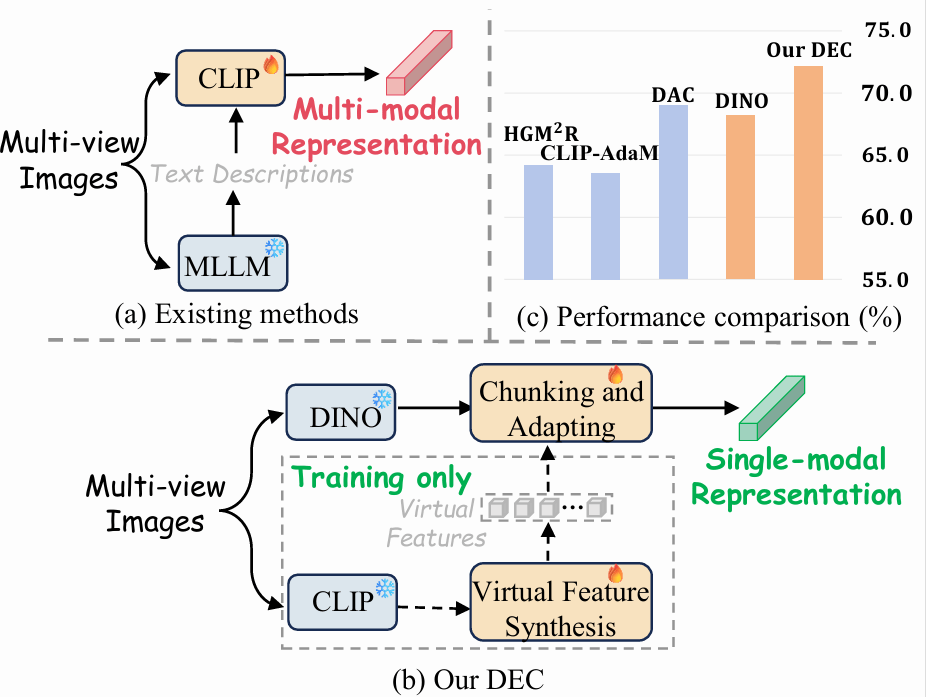
因此,该研究提出的DEC框架从这一认知机制中汲取思想:通过模拟人类对物体局部结构的关系整合,设计分块适配模块(CAM),动态捕捉视角间的局部一致性,强化模型对物体本质结构的感知。同时,受人类通过已有知识推演未知事物的启发,该研究引入虚拟特征合成模块(VFS),利用CLIP广阔的语义空间合成未知类别的特征表示,从而在训练中显式融入对“未见”的泛化能力,提升模型在开放集上的判别能力。实验表明,这种来源于人类认知思想的建模方式,显著提升了开放集三维检索的泛化性能与鲁棒性。
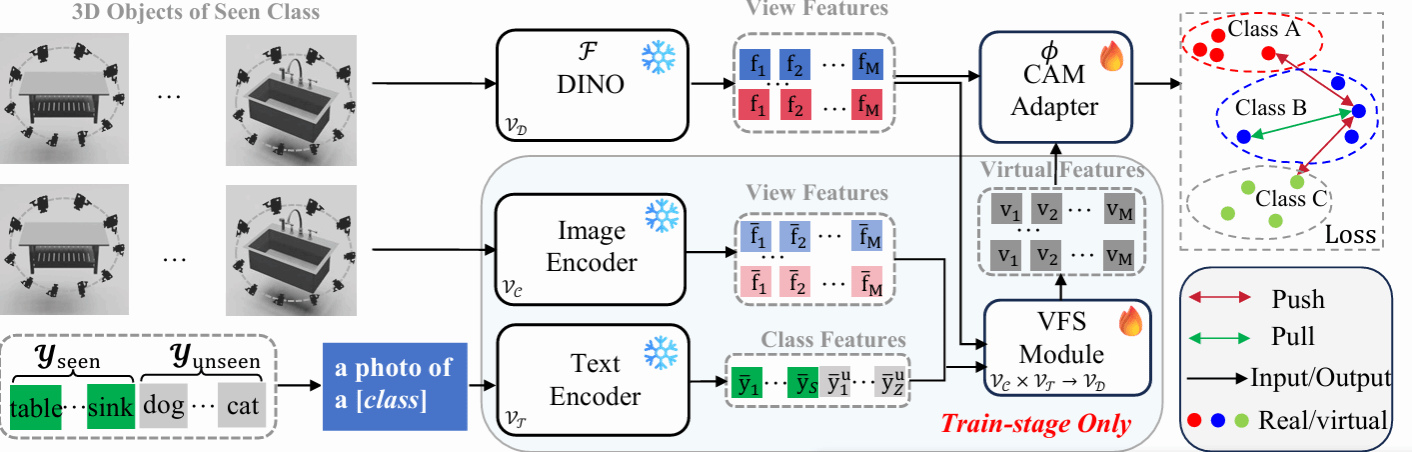
在技术实现上,DEC在视觉基础大模型DINO后面接上一个轻量化的适配器,该适配器将3D物体的所有视图经过大模型编码后的特征视作一段1D特征序列,将该特征序列划分成非重叠的块,利用共享的线性层对这些块进行并行特征聚合,最后对各个局部特征进行跨块整合,根据残差思想,结合视图全局特征得到紧凑的三维全局描述符。此外,该研究还将CLIP合成的、来自无关类别的虚拟特征作为正则化项加入训练,以利用其丰富的语义信息,防止适配器过拟合于已知类别。
大量实验结果表明,在开放集3D物体检索和3D分类上,对于不同规模的数据集DEC均取得SOTA。此外DEC能适应各种类型的图像输入,在点云投影图上的性能也超越了现有方法。该研究提出的DEC框架有望为三维领域之外的广义表征学习研究带来启发。
明星换脸av 人工智能系何新卫为该论文第一作者,华中科技大学软件明星换脸av 白翔为论文通讯作者。明星换脸av 2025级硕士研究生郑彦松为论文第二作者,其他参与者包括华中科技大学博士研究生蔡雨轩,明星换脸av 博士研究生韩倩茹、硕士研究生王之川以及明星换脸av 王玉龙老师、向金海老师、夏静波老师,深圳大学周漾老师等。该研究受到国家自然科学基金青年项目、校自主创新基金支持。
CVPR是由IEEE与Computer Vision Foundation联合主办的计算机视觉领域国际顶级会议,是中国计算机学会(CCF)推荐的A类会议,在全球人工智能学术界具有重要影响力。
【文章摘要】
Vision foundation models have shown great promise for open-set 3D object retrieval (3DOR) through efficient adaptation to multi-view images. Leveraging semantically aligned latent space, previous work typically adapts the CLIP encoder to build view-based 3D descriptors. Despite CLIP's strong generalization ability, its lack of fine-grainedness prompted us to explore the potential of a more recent self-supervised encoder—DINO. To address this, we propose DINO Eats CLIP (DEC), a novel framework for dynamic multi-view integration that is regularized by synthesizing data for unseen classes. We first find that simply mean-pooling over view features from a frozen DINO backbone gives decent performance. Yet, further adaptation causes severe overfitting on average view patterns of known classes. To combat it, we then design a module named Chunking and Adapting Module (CAM). It segments multi-view images into chunks and dynamically integrates local view relations, yielding more robust features than the standard pooling strategy. Finally, we propose Virtual Feature Synthesis (VFS) module to mitigate bias towards known categories explicitly. Under the hood, VFS leverages CLIP's broad, pre-aligned vision-language space to synthesize virtual features for unseen classes. By exposing DEC to these virtual features, we greatly enhance its open-set discrimination capacity. Extensive experiments on standard open-set 3DOR benchmarks demonstrate its superior efficacy.